- ![]() -
- ![]()

Meet HopeJR – A humanoid robot arm and hand for dexterous manipulation!
@@ -51,20 +47,12 @@ -
-  -
-  |
+  |
+
Meet the updated SO100, the SO-101 – Just €114 per arm!
Train it in minutes with a few simple moves on your laptop.
@@ -76,7 +64,7 @@Want to take it to the next level? Make your SO-101 mobile by building LeKiwi!
Check out the LeKiwi tutorial and bring your robot to life on wheels.
- +
+ 
 |
-  |
-  |
+  |
+  |
+  |
| ACT policy on ALOHA env | @@ -110,24 +98,9 @@
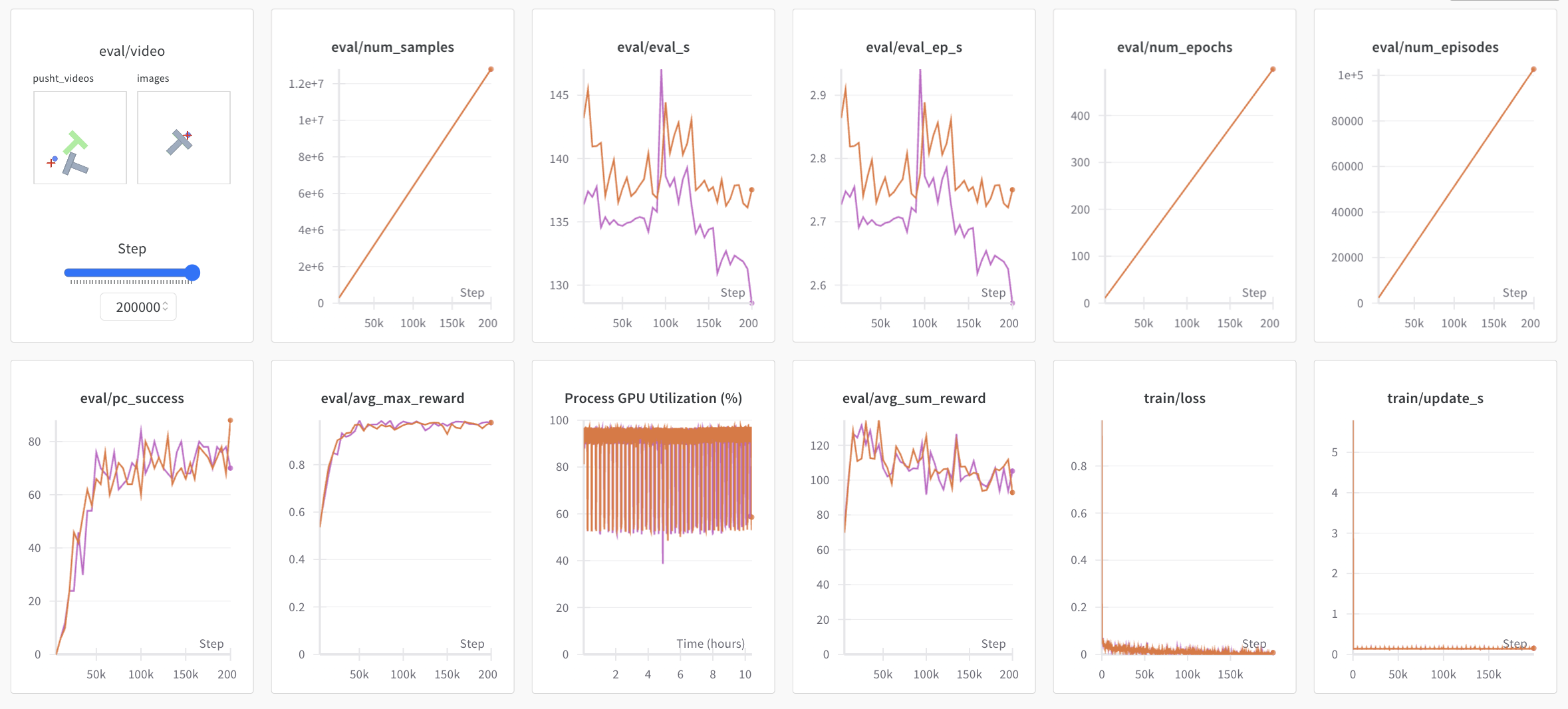 Note: For efficiency, during training every checkpoint is evaluated on a low number of episodes. You may use `--eval.n_episodes=500` to evaluate on more episodes than the default. Or, after training, you may want to re-evaluate your best checkpoints on more episodes or change the evaluation settings. See `python -m lerobot.scripts.eval --help` for more instructions.
@@ -305,26 +278,6 @@ reproduces SOTA results for Diffusion Policy on the PushT task.
If you would like to contribute to 🤗 LeRobot, please check out our [contribution guide](https://github.com/huggingface/lerobot/blob/main/CONTRIBUTING.md).
-
-
### Add a pretrained policy
Once you have trained a policy you may upload it to the Hugging Face hub using a hub id that looks like `${hf_user}/${repo_name}` (e.g. [lerobot/diffusion_pusht](https://huggingface.co/lerobot/diffusion_pusht)).
@@ -341,34 +294,16 @@ To upload these to the hub, run the following:
huggingface-cli upload ${hf_user}/${repo_name} path/to/pretrained_model
```
-See [eval.py](https://github.com/huggingface/lerobot/blob/main/lerobot/scripts/eval.py) for an example of how other people may use your policy.
+See [eval.py](https://github.com/huggingface/lerobot/blob/main/src/lerobot/scripts/eval.py) for an example of how other people may use your policy.
-### Improve your code with profiling
+### Acknowledgment
-An example of a code snippet to profile the evaluation of a policy:
-
-
-```python
-from torch.profiler import profile, record_function, ProfilerActivity
-
-def trace_handler(prof):
- prof.export_chrome_trace(f"tmp/trace_schedule_{prof.step_num}.json")
-
-with profile(
- activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],
- schedule=torch.profiler.schedule(
- wait=2,
- warmup=2,
- active=3,
- ),
- on_trace_ready=trace_handler
-) as prof:
- with record_function("eval_policy"):
- for i in range(num_episodes):
- prof.step()
- # insert code to profile, potentially whole body of eval_policy function
-```
-
+- The LeRobot team 🤗 for building SmolVLA [Paper](https://arxiv.org/abs/2506.01844), [Blog](https://huggingface.co/blog/smolvla).
+- Thanks to Tony Zhao, Zipeng Fu and colleagues for open sourcing ACT policy, ALOHA environments and datasets. Ours are adapted from [ALOHA](https://tonyzhaozh.github.io/aloha) and [Mobile ALOHA](https://mobile-aloha.github.io).
+- Thanks to Cheng Chi, Zhenjia Xu and colleagues for open sourcing Diffusion policy, Pusht environment and datasets, as well as UMI datasets. Ours are adapted from [Diffusion Policy](https://diffusion-policy.cs.columbia.edu) and [UMI Gripper](https://umi-gripper.github.io).
+- Thanks to Nicklas Hansen, Yunhai Feng and colleagues for open sourcing TDMPC policy, Simxarm environments and datasets. Ours are adapted from [TDMPC](https://github.com/nicklashansen/tdmpc) and [FOWM](https://www.yunhaifeng.com/FOWM).
+- Thanks to Antonio Loquercio and Ashish Kumar for their early support.
+- Thanks to [Seungjae (Jay) Lee](https://sjlee.cc/), [Mahi Shafiullah](https://mahis.life/) and colleagues for open sourcing [VQ-BeT](https://sjlee.cc/vq-bet/) policy and helping us adapt the codebase to our repository. The policy is adapted from [VQ-BeT repo](https://github.com/jayLEE0301/vq_bet_official).
## Citation
@@ -383,76 +318,6 @@ If you want, you can cite this work with:
}
```
-Additionally, if you are using any of the particular policy architecture, pretrained models, or datasets, it is recommended to cite the original authors of the work as they appear below:
-
-- [SmolVLA](https://arxiv.org/abs/2506.01844)
-
-```bibtex
-@article{shukor2025smolvla,
- title={SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics},
- author={Shukor, Mustafa and Aubakirova, Dana and Capuano, Francesco and Kooijmans, Pepijn and Palma, Steven and Zouitine, Adil and Aractingi, Michel and Pascal, Caroline and Russi, Martino and Marafioti, Andres and Alibert, Simon and Cord, Matthieu and Wolf, Thomas and Cadene, Remi},
- journal={arXiv preprint arXiv:2506.01844},
- year={2025}
-}
-```
-
-- [Diffusion Policy](https://diffusion-policy.cs.columbia.edu)
-
-```bibtex
-@article{chi2024diffusionpolicy,
- author = {Cheng Chi and Zhenjia Xu and Siyuan Feng and Eric Cousineau and Yilun Du and Benjamin Burchfiel and Russ Tedrake and Shuran Song},
- title ={Diffusion Policy: Visuomotor Policy Learning via Action Diffusion},
- journal = {The International Journal of Robotics Research},
- year = {2024},
-}
-```
-
-- [ACT or ALOHA](https://tonyzhaozh.github.io/aloha)
-
-```bibtex
-@article{zhao2023learning,
- title={Learning fine-grained bimanual manipulation with low-cost hardware},
- author={Zhao, Tony Z and Kumar, Vikash and Levine, Sergey and Finn, Chelsea},
- journal={arXiv preprint arXiv:2304.13705},
- year={2023}
-}
-```
-
-- [TDMPC](https://www.nicklashansen.com/td-mpc/)
-
-```bibtex
-@inproceedings{Hansen2022tdmpc,
- title={Temporal Difference Learning for Model Predictive Control},
- author={Nicklas Hansen and Xiaolong Wang and Hao Su},
- booktitle={ICML},
- year={2022}
-}
-```
-
-- [VQ-BeT](https://sjlee.cc/vq-bet/)
-
-```bibtex
-@article{lee2024behavior,
- title={Behavior generation with latent actions},
- author={Lee, Seungjae and Wang, Yibin and Etukuru, Haritheja and Kim, H Jin and Shafiullah, Nur Muhammad Mahi and Pinto, Lerrel},
- journal={arXiv preprint arXiv:2403.03181},
- year={2024}
-}
-```
-
-- [HIL-SERL](https://hil-serl.github.io/)
-
-```bibtex
-@Article{luo2024hilserl,
-title={Precise and Dexterous Robotic Manipulation via Human-in-the-Loop Reinforcement Learning},
-author={Jianlan Luo and Charles Xu and Jeffrey Wu and Sergey Levine},
-year={2024},
-eprint={2410.21845},
-archivePrefix={arXiv},
-primaryClass={cs.RO}
-}
-```
-
## Star History
[](https://star-history.com/#huggingface/lerobot&Timeline)
diff --git a/docs/source/policy_act_README.md b/docs/source/policy_act_README.md
new file mode 100644
index 00000000..371a9136
--- /dev/null
+++ b/docs/source/policy_act_README.md
@@ -0,0 +1,14 @@
+## Paper
+
+https://tonyzhaozh.github.io/aloha
+
+## Citation
+
+```bibtex
+@article{zhao2023learning,
+ title={Learning fine-grained bimanual manipulation with low-cost hardware},
+ author={Zhao, Tony Z and Kumar, Vikash and Levine, Sergey and Finn, Chelsea},
+ journal={arXiv preprint arXiv:2304.13705},
+ year={2023}
+}
+```
diff --git a/docs/source/policy_diffusion_README.md b/docs/source/policy_diffusion_README.md
new file mode 100644
index 00000000..9ec934ad
--- /dev/null
+++ b/docs/source/policy_diffusion_README.md
@@ -0,0 +1,14 @@
+## Paper
+
+https://diffusion-policy.cs.columbia.edu
+
+## Citation
+
+```bibtex
+@article{chi2024diffusionpolicy,
+ author = {Cheng Chi and Zhenjia Xu and Siyuan Feng and Eric Cousineau and Yilun Du and Benjamin Burchfiel and Russ Tedrake and Shuran Song},
+ title ={Diffusion Policy: Visuomotor Policy Learning via Action Diffusion},
+ journal = {The International Journal of Robotics Research},
+ year = {2024},
+}
+```
diff --git a/docs/source/policy_smolvla_README.md b/docs/source/policy_smolvla_README.md
new file mode 100644
index 00000000..ee567ee8
--- /dev/null
+++ b/docs/source/policy_smolvla_README.md
@@ -0,0 +1,14 @@
+## Paper
+
+https://arxiv.org/abs/2506.01844
+
+## Citation
+
+```bibtex
+@article{shukor2025smolvla,
+ title={SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics},
+ author={Shukor, Mustafa and Aubakirova, Dana and Capuano, Francesco and Kooijmans, Pepijn and Palma, Steven and Zouitine, Adil and Aractingi, Michel and Pascal, Caroline and Russi, Martino and Marafioti, Andres and Alibert, Simon and Cord, Matthieu and Wolf, Thomas and Cadene, Remi},
+ journal={arXiv preprint arXiv:2506.01844},
+ year={2025}
+}
+```
diff --git a/docs/source/policy_tdmpc_README.md b/docs/source/policy_tdmpc_README.md
new file mode 100644
index 00000000..804f166c
--- /dev/null
+++ b/docs/source/policy_tdmpc_README.md
@@ -0,0 +1,14 @@
+## Paper
+
+https://www.nicklashansen.com/td-mpc/
+
+## Citation
+
+```bibtex
+@inproceedings{Hansen2022tdmpc,
+ title={Temporal Difference Learning for Model Predictive Control},
+ author={Nicklas Hansen and Xiaolong Wang and Hao Su},
+ booktitle={ICML},
+ year={2022}
+}
+```
diff --git a/docs/source/policy_vqbet_README.md b/docs/source/policy_vqbet_README.md
new file mode 100644
index 00000000..02f95b7c
--- /dev/null
+++ b/docs/source/policy_vqbet_README.md
@@ -0,0 +1,14 @@
+## Paper
+
+https://sjlee.cc/vq-bet/
+
+## Citation
+
+```bibtex
+@article{lee2024behavior,
+ title={Behavior generation with latent actions},
+ author={Lee, Seungjae and Wang, Yibin and Etukuru, Haritheja and Kim, H Jin and Shafiullah, Nur Muhammad Mahi and Pinto, Lerrel},
+ journal={arXiv preprint arXiv:2403.03181},
+ year={2024}
+}
+```
diff --git a/src/lerobot/policies/act/README.md b/src/lerobot/policies/act/README.md
new file mode 120000
index 00000000..04602009
--- /dev/null
+++ b/src/lerobot/policies/act/README.md
@@ -0,0 +1 @@
+../../../../docs/source/policy_act_README.md
\ No newline at end of file
diff --git a/src/lerobot/policies/diffusion/README.md b/src/lerobot/policies/diffusion/README.md
new file mode 120000
index 00000000..d332d79c
--- /dev/null
+++ b/src/lerobot/policies/diffusion/README.md
@@ -0,0 +1 @@
+../../../../docs/source/policy_diffusion_README.md
\ No newline at end of file
diff --git a/src/lerobot/policies/smolvla/README.md b/src/lerobot/policies/smolvla/README.md
new file mode 120000
index 00000000..f8de4026
--- /dev/null
+++ b/src/lerobot/policies/smolvla/README.md
@@ -0,0 +1 @@
+../../../../docs/source/policy_smolvla_README.md
\ No newline at end of file
diff --git a/src/lerobot/policies/tdmpc/README.md b/src/lerobot/policies/tdmpc/README.md
new file mode 120000
index 00000000..413ea87b
--- /dev/null
+++ b/src/lerobot/policies/tdmpc/README.md
@@ -0,0 +1 @@
+../../../../docs/source/policy_tdmpc_README.md
\ No newline at end of file
diff --git a/src/lerobot/policies/vqbet/README.md b/src/lerobot/policies/vqbet/README.md
new file mode 120000
index 00000000..a4ae9291
--- /dev/null
+++ b/src/lerobot/policies/vqbet/README.md
@@ -0,0 +1 @@
+../../../../docs/source/policy_vqbet_README.md
\ No newline at end of file
Note: For efficiency, during training every checkpoint is evaluated on a low number of episodes. You may use `--eval.n_episodes=500` to evaluate on more episodes than the default. Or, after training, you may want to re-evaluate your best checkpoints on more episodes or change the evaluation settings. See `python -m lerobot.scripts.eval --help` for more instructions.
@@ -305,26 +278,6 @@ reproduces SOTA results for Diffusion Policy on the PushT task.
If you would like to contribute to 🤗 LeRobot, please check out our [contribution guide](https://github.com/huggingface/lerobot/blob/main/CONTRIBUTING.md).
-
-
### Add a pretrained policy
Once you have trained a policy you may upload it to the Hugging Face hub using a hub id that looks like `${hf_user}/${repo_name}` (e.g. [lerobot/diffusion_pusht](https://huggingface.co/lerobot/diffusion_pusht)).
@@ -341,34 +294,16 @@ To upload these to the hub, run the following:
huggingface-cli upload ${hf_user}/${repo_name} path/to/pretrained_model
```
-See [eval.py](https://github.com/huggingface/lerobot/blob/main/lerobot/scripts/eval.py) for an example of how other people may use your policy.
+See [eval.py](https://github.com/huggingface/lerobot/blob/main/src/lerobot/scripts/eval.py) for an example of how other people may use your policy.
-### Improve your code with profiling
+### Acknowledgment
-An example of a code snippet to profile the evaluation of a policy:
-
-
-```python
-from torch.profiler import profile, record_function, ProfilerActivity
-
-def trace_handler(prof):
- prof.export_chrome_trace(f"tmp/trace_schedule_{prof.step_num}.json")
-
-with profile(
- activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],
- schedule=torch.profiler.schedule(
- wait=2,
- warmup=2,
- active=3,
- ),
- on_trace_ready=trace_handler
-) as prof:
- with record_function("eval_policy"):
- for i in range(num_episodes):
- prof.step()
- # insert code to profile, potentially whole body of eval_policy function
-```
-
+- The LeRobot team 🤗 for building SmolVLA [Paper](https://arxiv.org/abs/2506.01844), [Blog](https://huggingface.co/blog/smolvla).
+- Thanks to Tony Zhao, Zipeng Fu and colleagues for open sourcing ACT policy, ALOHA environments and datasets. Ours are adapted from [ALOHA](https://tonyzhaozh.github.io/aloha) and [Mobile ALOHA](https://mobile-aloha.github.io).
+- Thanks to Cheng Chi, Zhenjia Xu and colleagues for open sourcing Diffusion policy, Pusht environment and datasets, as well as UMI datasets. Ours are adapted from [Diffusion Policy](https://diffusion-policy.cs.columbia.edu) and [UMI Gripper](https://umi-gripper.github.io).
+- Thanks to Nicklas Hansen, Yunhai Feng and colleagues for open sourcing TDMPC policy, Simxarm environments and datasets. Ours are adapted from [TDMPC](https://github.com/nicklashansen/tdmpc) and [FOWM](https://www.yunhaifeng.com/FOWM).
+- Thanks to Antonio Loquercio and Ashish Kumar for their early support.
+- Thanks to [Seungjae (Jay) Lee](https://sjlee.cc/), [Mahi Shafiullah](https://mahis.life/) and colleagues for open sourcing [VQ-BeT](https://sjlee.cc/vq-bet/) policy and helping us adapt the codebase to our repository. The policy is adapted from [VQ-BeT repo](https://github.com/jayLEE0301/vq_bet_official).
## Citation
@@ -383,76 +318,6 @@ If you want, you can cite this work with:
}
```
-Additionally, if you are using any of the particular policy architecture, pretrained models, or datasets, it is recommended to cite the original authors of the work as they appear below:
-
-- [SmolVLA](https://arxiv.org/abs/2506.01844)
-
-```bibtex
-@article{shukor2025smolvla,
- title={SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics},
- author={Shukor, Mustafa and Aubakirova, Dana and Capuano, Francesco and Kooijmans, Pepijn and Palma, Steven and Zouitine, Adil and Aractingi, Michel and Pascal, Caroline and Russi, Martino and Marafioti, Andres and Alibert, Simon and Cord, Matthieu and Wolf, Thomas and Cadene, Remi},
- journal={arXiv preprint arXiv:2506.01844},
- year={2025}
-}
-```
-
-- [Diffusion Policy](https://diffusion-policy.cs.columbia.edu)
-
-```bibtex
-@article{chi2024diffusionpolicy,
- author = {Cheng Chi and Zhenjia Xu and Siyuan Feng and Eric Cousineau and Yilun Du and Benjamin Burchfiel and Russ Tedrake and Shuran Song},
- title ={Diffusion Policy: Visuomotor Policy Learning via Action Diffusion},
- journal = {The International Journal of Robotics Research},
- year = {2024},
-}
-```
-
-- [ACT or ALOHA](https://tonyzhaozh.github.io/aloha)
-
-```bibtex
-@article{zhao2023learning,
- title={Learning fine-grained bimanual manipulation with low-cost hardware},
- author={Zhao, Tony Z and Kumar, Vikash and Levine, Sergey and Finn, Chelsea},
- journal={arXiv preprint arXiv:2304.13705},
- year={2023}
-}
-```
-
-- [TDMPC](https://www.nicklashansen.com/td-mpc/)
-
-```bibtex
-@inproceedings{Hansen2022tdmpc,
- title={Temporal Difference Learning for Model Predictive Control},
- author={Nicklas Hansen and Xiaolong Wang and Hao Su},
- booktitle={ICML},
- year={2022}
-}
-```
-
-- [VQ-BeT](https://sjlee.cc/vq-bet/)
-
-```bibtex
-@article{lee2024behavior,
- title={Behavior generation with latent actions},
- author={Lee, Seungjae and Wang, Yibin and Etukuru, Haritheja and Kim, H Jin and Shafiullah, Nur Muhammad Mahi and Pinto, Lerrel},
- journal={arXiv preprint arXiv:2403.03181},
- year={2024}
-}
-```
-
-- [HIL-SERL](https://hil-serl.github.io/)
-
-```bibtex
-@Article{luo2024hilserl,
-title={Precise and Dexterous Robotic Manipulation via Human-in-the-Loop Reinforcement Learning},
-author={Jianlan Luo and Charles Xu and Jeffrey Wu and Sergey Levine},
-year={2024},
-eprint={2410.21845},
-archivePrefix={arXiv},
-primaryClass={cs.RO}
-}
-```
-
## Star History
[](https://star-history.com/#huggingface/lerobot&Timeline)
diff --git a/docs/source/policy_act_README.md b/docs/source/policy_act_README.md
new file mode 100644
index 00000000..371a9136
--- /dev/null
+++ b/docs/source/policy_act_README.md
@@ -0,0 +1,14 @@
+## Paper
+
+https://tonyzhaozh.github.io/aloha
+
+## Citation
+
+```bibtex
+@article{zhao2023learning,
+ title={Learning fine-grained bimanual manipulation with low-cost hardware},
+ author={Zhao, Tony Z and Kumar, Vikash and Levine, Sergey and Finn, Chelsea},
+ journal={arXiv preprint arXiv:2304.13705},
+ year={2023}
+}
+```
diff --git a/docs/source/policy_diffusion_README.md b/docs/source/policy_diffusion_README.md
new file mode 100644
index 00000000..9ec934ad
--- /dev/null
+++ b/docs/source/policy_diffusion_README.md
@@ -0,0 +1,14 @@
+## Paper
+
+https://diffusion-policy.cs.columbia.edu
+
+## Citation
+
+```bibtex
+@article{chi2024diffusionpolicy,
+ author = {Cheng Chi and Zhenjia Xu and Siyuan Feng and Eric Cousineau and Yilun Du and Benjamin Burchfiel and Russ Tedrake and Shuran Song},
+ title ={Diffusion Policy: Visuomotor Policy Learning via Action Diffusion},
+ journal = {The International Journal of Robotics Research},
+ year = {2024},
+}
+```
diff --git a/docs/source/policy_smolvla_README.md b/docs/source/policy_smolvla_README.md
new file mode 100644
index 00000000..ee567ee8
--- /dev/null
+++ b/docs/source/policy_smolvla_README.md
@@ -0,0 +1,14 @@
+## Paper
+
+https://arxiv.org/abs/2506.01844
+
+## Citation
+
+```bibtex
+@article{shukor2025smolvla,
+ title={SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics},
+ author={Shukor, Mustafa and Aubakirova, Dana and Capuano, Francesco and Kooijmans, Pepijn and Palma, Steven and Zouitine, Adil and Aractingi, Michel and Pascal, Caroline and Russi, Martino and Marafioti, Andres and Alibert, Simon and Cord, Matthieu and Wolf, Thomas and Cadene, Remi},
+ journal={arXiv preprint arXiv:2506.01844},
+ year={2025}
+}
+```
diff --git a/docs/source/policy_tdmpc_README.md b/docs/source/policy_tdmpc_README.md
new file mode 100644
index 00000000..804f166c
--- /dev/null
+++ b/docs/source/policy_tdmpc_README.md
@@ -0,0 +1,14 @@
+## Paper
+
+https://www.nicklashansen.com/td-mpc/
+
+## Citation
+
+```bibtex
+@inproceedings{Hansen2022tdmpc,
+ title={Temporal Difference Learning for Model Predictive Control},
+ author={Nicklas Hansen and Xiaolong Wang and Hao Su},
+ booktitle={ICML},
+ year={2022}
+}
+```
diff --git a/docs/source/policy_vqbet_README.md b/docs/source/policy_vqbet_README.md
new file mode 100644
index 00000000..02f95b7c
--- /dev/null
+++ b/docs/source/policy_vqbet_README.md
@@ -0,0 +1,14 @@
+## Paper
+
+https://sjlee.cc/vq-bet/
+
+## Citation
+
+```bibtex
+@article{lee2024behavior,
+ title={Behavior generation with latent actions},
+ author={Lee, Seungjae and Wang, Yibin and Etukuru, Haritheja and Kim, H Jin and Shafiullah, Nur Muhammad Mahi and Pinto, Lerrel},
+ journal={arXiv preprint arXiv:2403.03181},
+ year={2024}
+}
+```
diff --git a/src/lerobot/policies/act/README.md b/src/lerobot/policies/act/README.md
new file mode 120000
index 00000000..04602009
--- /dev/null
+++ b/src/lerobot/policies/act/README.md
@@ -0,0 +1 @@
+../../../../docs/source/policy_act_README.md
\ No newline at end of file
diff --git a/src/lerobot/policies/diffusion/README.md b/src/lerobot/policies/diffusion/README.md
new file mode 120000
index 00000000..d332d79c
--- /dev/null
+++ b/src/lerobot/policies/diffusion/README.md
@@ -0,0 +1 @@
+../../../../docs/source/policy_diffusion_README.md
\ No newline at end of file
diff --git a/src/lerobot/policies/smolvla/README.md b/src/lerobot/policies/smolvla/README.md
new file mode 120000
index 00000000..f8de4026
--- /dev/null
+++ b/src/lerobot/policies/smolvla/README.md
@@ -0,0 +1 @@
+../../../../docs/source/policy_smolvla_README.md
\ No newline at end of file
diff --git a/src/lerobot/policies/tdmpc/README.md b/src/lerobot/policies/tdmpc/README.md
new file mode 120000
index 00000000..413ea87b
--- /dev/null
+++ b/src/lerobot/policies/tdmpc/README.md
@@ -0,0 +1 @@
+../../../../docs/source/policy_tdmpc_README.md
\ No newline at end of file
diff --git a/src/lerobot/policies/vqbet/README.md b/src/lerobot/policies/vqbet/README.md
new file mode 120000
index 00000000..a4ae9291
--- /dev/null
+++ b/src/lerobot/policies/vqbet/README.md
@@ -0,0 +1 @@
+../../../../docs/source/policy_vqbet_README.md
\ No newline at end of file