feat(sim): Add Libero Env (#1984)
This commit is contained in:
@@ -39,6 +39,7 @@ RUN apt-get update && apt-get install -y --no-install-recommends \
|
||||
software-properties-common build-essential git curl \
|
||||
libglib2.0-0 libgl1-mesa-glx libegl1-mesa ffmpeg \
|
||||
libusb-1.0-0-dev speech-dispatcher libgeos-dev portaudio19-dev \
|
||||
cmake pkg-config ninja-build \
|
||||
&& add-apt-repository -y ppa:deadsnakes/ppa \
|
||||
&& apt-get update \
|
||||
&& apt-get install -y --no-install-recommends \
|
||||
|
||||
@@ -31,6 +31,7 @@ ENV DEBIAN_FRONTEND=noninteractive \
|
||||
RUN apt-get update && apt-get install -y --no-install-recommends \
|
||||
build-essential git curl libglib2.0-0 libegl1-mesa-dev ffmpeg \
|
||||
libusb-1.0-0-dev speech-dispatcher libgeos-dev portaudio19-dev \
|
||||
cmake pkg-config ninja-build \
|
||||
&& curl -LsSf https://astral.sh/uv/install.sh | sh \
|
||||
&& mv /root/.local/bin/uv /usr/local/bin/uv \
|
||||
&& useradd --create-home --shell /bin/bash user_lerobot \
|
||||
|
||||
@@ -29,6 +29,8 @@
|
||||
- sections:
|
||||
- local: smolvla
|
||||
title: Finetune SmolVLA
|
||||
- local: libero
|
||||
title: Using Libero
|
||||
title: "Policies"
|
||||
|
||||
- sections:
|
||||
|
||||
126
docs/source/libero.mdx
Normal file
126
docs/source/libero.mdx
Normal file
@@ -0,0 +1,126 @@
|
||||
# LIBERO
|
||||
|
||||
**LIBERO** is a benchmark designed to study **lifelong robot learning**. The idea is that robots won’t just be pretrained once in a factory, they’ll need to keep learning and adapting with their human users over time. This ongoing adaptation is called **lifelong learning in decision making (LLDM)**, and it’s a key step toward building robots that become truly personalized helpers.
|
||||
|
||||
- 📄 [LIBERO paper](https://arxiv.org/abs/2306.03310)
|
||||
- 💻 [Original LIBERO repo](https://github.com/Lifelong-Robot-Learning/LIBERO)
|
||||
|
||||
To make progress on this challenge, LIBERO provides a set of standardized tasks that focus on **knowledge transfer**: how well a robot can apply what it has already learned to new situations. By evaluating on LIBERO, different algorithms can be compared fairly and researchers can build on each other’s work.
|
||||
|
||||
LIBERO includes **five task suites**:
|
||||
|
||||
- **LIBERO-Spatial (`libero_spatial`)** – tasks that require reasoning about spatial relations.
|
||||
- **LIBERO-Object (`libero_object`)** – tasks centered on manipulating different objects.
|
||||
- **LIBERO-Goal (`libero_goal`)** – goal-conditioned tasks where the robot must adapt to changing targets.
|
||||
- **LIBERO-90 (`libero_90`)** – 90 short-horizon tasks from the LIBERO-100 collection.
|
||||
- **LIBERO-Long (`libero_10`)** – 10 long-horizon tasks from the LIBERO-100 collection.
|
||||
|
||||
Together, these suites cover **130 tasks**, ranging from simple object manipulations to complex multi-step scenarios. LIBERO is meant to grow over time, and to serve as a shared benchmark where the community can test and improve lifelong learning algorithms.
|
||||
|
||||
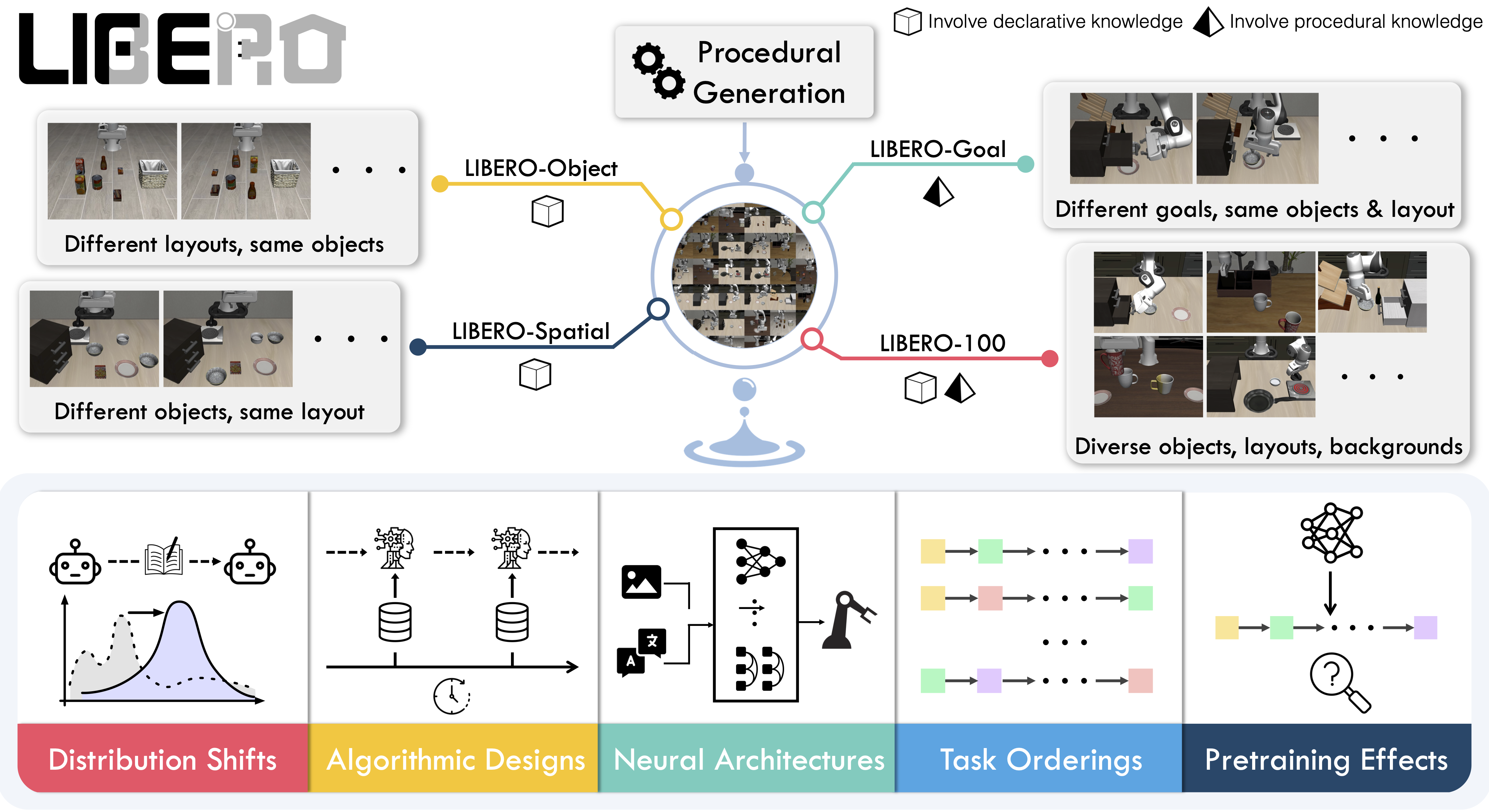
|
||||
|
||||
## Evaluating with LIBERO
|
||||
|
||||
At **LeRobot**, we ported [LIBERO](https://github.com/Lifelong-Robot-Learning/LIBERO) into our framework and used it mainly to **evaluate [SmolVLA](https://huggingface.co/docs/lerobot/en/smolvla)**, our lightweight Vision-Language-Action model.
|
||||
|
||||
LIBERO is now part of our **multi-eval supported simulation**, meaning you can benchmark your policies either on a **single suite of tasks** or across **multiple suites at once** with just a flag.
|
||||
|
||||
To Install LIBERO, after following LeRobot official instructions, just do:
|
||||
`pip install -e ".[libero]"`
|
||||
|
||||
### Single-suite evaluation
|
||||
|
||||
Evaluate a policy on one LIBERO suite:
|
||||
|
||||
```bash
|
||||
python src/lerobot/scripts/eval.py \
|
||||
--policy.path="your-policy-id" \
|
||||
--env.type=libero \
|
||||
--env.task=libero_object \
|
||||
--eval.batch_size=2 \
|
||||
--eval.n_episodes=3
|
||||
```
|
||||
|
||||
- `--env.task` picks the suite (`libero_object`, `libero_spatial`, etc.).
|
||||
- `--eval.batch_size` controls how many environments run in parallel.
|
||||
- `--eval.n_episodes` sets how many episodes to run in total.
|
||||
|
||||
---
|
||||
|
||||
### Multi-suite evaluation
|
||||
|
||||
Benchmark a policy across multiple suites at once:
|
||||
|
||||
```bash
|
||||
python src/lerobot/scripts/eval.py \
|
||||
--policy.path="your-policy-id" \
|
||||
--env.type=libero \
|
||||
--env.task=libero_object,libero_spatial \
|
||||
--eval.batch_size=1 \
|
||||
--eval.n_episodes=2
|
||||
```
|
||||
|
||||
- Pass a comma-separated list to `--env.task` for multi-suite evaluation.
|
||||
|
||||
### Policy inputs and outputs
|
||||
|
||||
When using LIBERO through LeRobot, policies interact with the environment via **observations** and **actions**:
|
||||
|
||||
- **Observations**
|
||||
- `observation.state` – proprioceptive features (agent state).
|
||||
- `observation.images.image` – main camera view (`agentview_image`).
|
||||
- `observation.images.image2` – wrist camera view (`robot0_eye_in_hand_image`).
|
||||
|
||||
⚠️ **Note:** LeRobot enforces the `.images.*` prefix for any multi-modal visual features. Always ensure that your policy config `input_features` use the same naming keys, and that your dataset metadata keys follow this convention during evaluation.
|
||||
If your data contains different keys, you must rename the observations to match what the policy expects, since naming keys are encoded inside the normalization statistics layer.
|
||||
This will be fixed with the upcoming Pipeline PR.
|
||||
|
||||
- **Actions**
|
||||
- Continuous control values in a `Box(-1, 1, shape=(7,))` space.
|
||||
|
||||
We also provide a notebook for quick testing:
|
||||
Training with LIBERO
|
||||
|
||||
## Training with LIBERO
|
||||
|
||||
When training on LIBERO tasks, make sure your dataset parquet and metadata keys follow the LeRobot convention.
|
||||
|
||||
The environment expects:
|
||||
|
||||
- `observation.state` → 8-dim agent state
|
||||
- `observation.images.image` → main camera (`agentview_image`)
|
||||
- `observation.images.image2` → wrist camera (`robot0_eye_in_hand_image`)
|
||||
|
||||
⚠️ Cleaning the dataset upfront is **cleaner and more efficient** than remapping keys inside the code.
|
||||
To avoid potential mismatches and key errors, we provide a **preprocessed LIBERO dataset** that is fully compatible with the current LeRobot codebase and requires no additional manipulation:
|
||||
👉 [HuggingFaceVLA/libero](https://huggingface.co/datasets/HuggingFaceVLA/libero)
|
||||
|
||||
For reference, here is the **original dataset** published by Physical Intelligence:
|
||||
👉 [physical-intelligence/libero](https://huggingface.co/datasets/physical-intelligence/libero)
|
||||
|
||||
---
|
||||
|
||||
### Example training command
|
||||
|
||||
```bash
|
||||
python src/lerobot/scripts/train.py \
|
||||
--policy.type=smolvla \
|
||||
--policy.repo_id=${HF_USER}/libero-test \
|
||||
--dataset.repo_id=jadechoghari/smol-libero3 \
|
||||
--env.type=libero \
|
||||
--env.task=libero_10 \
|
||||
--output_dir=./outputs/ \
|
||||
--steps=100000 \
|
||||
--batch_size=4 \
|
||||
--eval.batch_size=1 \
|
||||
--eval.n_episodes=1 \
|
||||
--eval_freq=1000 \
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### Note on rendering
|
||||
|
||||
LeRobot uses MuJoCo for simulation. You need to set the rendering backend before training or evaluation:
|
||||
|
||||
- `export MUJOCO_GL=egl` → for headless servers (e.g. HPC, cloud)
|
||||
@@ -135,6 +135,8 @@ video_benchmark = ["scikit-image>=0.23.2", "pandas>=2.2.2"]
|
||||
aloha = ["gym-aloha>=0.1.1"]
|
||||
pusht = ["gym-pusht>=0.1.5", "pymunk>=6.6.0,<7.0.0"] # TODO: Fix pymunk version in gym-pusht instead
|
||||
xarm = ["gym-xarm>=0.1.1"]
|
||||
libero = ["lerobot[transformers-dep]", "libero @ git+https://github.com/huggingface/lerobot-libero.git@main#egg=libero"]
|
||||
|
||||
|
||||
# All
|
||||
all = [
|
||||
@@ -156,6 +158,7 @@ all = [
|
||||
"lerobot[pusht]",
|
||||
"lerobot[xarm]",
|
||||
"lerobot[phone]",
|
||||
"lerobot[libero]",
|
||||
]
|
||||
|
||||
[project.scripts]
|
||||
|
||||
@@ -30,6 +30,8 @@ class EnvConfig(draccus.ChoiceRegistry, abc.ABC):
|
||||
fps: int = 30
|
||||
features: dict[str, PolicyFeature] = field(default_factory=dict)
|
||||
features_map: dict[str, str] = field(default_factory=dict)
|
||||
max_parallel_tasks: int = 1
|
||||
disable_env_checker: bool = True
|
||||
|
||||
@property
|
||||
def type(self) -> str:
|
||||
@@ -242,3 +244,55 @@ class HILSerlRobotEnvConfig(EnvConfig):
|
||||
@property
|
||||
def gym_kwargs(self) -> dict:
|
||||
return {}
|
||||
|
||||
|
||||
@EnvConfig.register_subclass("libero")
|
||||
@dataclass
|
||||
class LiberoEnv(EnvConfig):
|
||||
task: str = "libero_10" # can also choose libero_spatial, libero_object, etc.
|
||||
fps: int = 30
|
||||
episode_length: int = 520
|
||||
obs_type: str = "pixels_agent_pos"
|
||||
render_mode: str = "rgb_array"
|
||||
camera_name: str = "agentview_image,robot0_eye_in_hand_image"
|
||||
init_states: bool = True
|
||||
camera_name_mapping: dict[str, str] | None = (None,)
|
||||
features: dict[str, PolicyFeature] = field(
|
||||
default_factory=lambda: {
|
||||
"action": PolicyFeature(type=FeatureType.ACTION, shape=(7,)),
|
||||
}
|
||||
)
|
||||
features_map: dict[str, str] = field(
|
||||
default_factory=lambda: {
|
||||
"action": ACTION,
|
||||
"agent_pos": OBS_STATE,
|
||||
"pixels/agentview_image": f"{OBS_IMAGES}.image",
|
||||
"pixels/robot0_eye_in_hand_image": f"{OBS_IMAGES}.image2",
|
||||
}
|
||||
)
|
||||
|
||||
def __post_init__(self):
|
||||
if self.obs_type == "pixels":
|
||||
self.features["pixels/agentview_image"] = PolicyFeature(
|
||||
type=FeatureType.VISUAL, shape=(360, 360, 3)
|
||||
)
|
||||
self.features["pixels/robot0_eye_in_hand_image"] = PolicyFeature(
|
||||
type=FeatureType.VISUAL, shape=(360, 360, 3)
|
||||
)
|
||||
elif self.obs_type == "pixels_agent_pos":
|
||||
self.features["agent_pos"] = PolicyFeature(type=FeatureType.STATE, shape=(8,))
|
||||
self.features["pixels/agentview_image"] = PolicyFeature(
|
||||
type=FeatureType.VISUAL, shape=(360, 360, 3)
|
||||
)
|
||||
self.features["pixels/robot0_eye_in_hand_image"] = PolicyFeature(
|
||||
type=FeatureType.VISUAL, shape=(360, 360, 3)
|
||||
)
|
||||
else:
|
||||
raise ValueError(f"Unsupported obs_type: {self.obs_type}")
|
||||
|
||||
@property
|
||||
def gym_kwargs(self) -> dict:
|
||||
return {
|
||||
"obs_type": self.obs_type,
|
||||
"render_mode": self.render_mode,
|
||||
}
|
||||
|
||||
@@ -17,7 +17,7 @@ import importlib
|
||||
|
||||
import gymnasium as gym
|
||||
|
||||
from lerobot.envs.configs import AlohaEnv, EnvConfig, PushtEnv, XarmEnv
|
||||
from lerobot.envs.configs import AlohaEnv, EnvConfig, LiberoEnv, PushtEnv, XarmEnv
|
||||
|
||||
|
||||
def make_env_config(env_type: str, **kwargs) -> EnvConfig:
|
||||
@@ -27,11 +27,15 @@ def make_env_config(env_type: str, **kwargs) -> EnvConfig:
|
||||
return PushtEnv(**kwargs)
|
||||
elif env_type == "xarm":
|
||||
return XarmEnv(**kwargs)
|
||||
elif env_type == "libero":
|
||||
return LiberoEnv(**kwargs)
|
||||
else:
|
||||
raise ValueError(f"Policy type '{env_type}' is not available.")
|
||||
|
||||
|
||||
def make_env(cfg: EnvConfig, n_envs: int = 1, use_async_envs: bool = False) -> gym.vector.VectorEnv | None:
|
||||
def make_env(
|
||||
cfg: EnvConfig, n_envs: int = 1, use_async_envs: bool = False
|
||||
) -> dict[str, dict[int, gym.vector.VectorEnv]]:
|
||||
"""Makes a gym vector environment according to the config.
|
||||
|
||||
Args:
|
||||
@@ -45,13 +49,30 @@ def make_env(cfg: EnvConfig, n_envs: int = 1, use_async_envs: bool = False) -> g
|
||||
ModuleNotFoundError: If the requested env package is not installed
|
||||
|
||||
Returns:
|
||||
gym.vector.VectorEnv: The parallelized gym.env instance.
|
||||
dict[str, dict[int, gym.vector.VectorEnv]]:
|
||||
A mapping from suite name to indexed vectorized environments.
|
||||
- For multi-task benchmarks (e.g., LIBERO): one entry per suite, and one vec env per task_id.
|
||||
- For single-task environments: a single suite entry (cfg.type) with task_id=0.
|
||||
|
||||
"""
|
||||
if n_envs < 1:
|
||||
raise ValueError("`n_envs must be at least 1")
|
||||
raise ValueError("`n_envs` must be at least 1")
|
||||
|
||||
env_cls = gym.vector.AsyncVectorEnv if use_async_envs else gym.vector.SyncVectorEnv
|
||||
|
||||
if "libero" in cfg.type:
|
||||
from lerobot.envs.libero import create_libero_envs
|
||||
|
||||
return create_libero_envs(
|
||||
task=cfg.task,
|
||||
n_envs=n_envs,
|
||||
camera_name=cfg.camera_name,
|
||||
init_states=cfg.init_states,
|
||||
gym_kwargs=cfg.gym_kwargs,
|
||||
env_cls=env_cls,
|
||||
)
|
||||
|
||||
package_name = f"gym_{cfg.type}"
|
||||
|
||||
try:
|
||||
importlib.import_module(package_name)
|
||||
except ModuleNotFoundError as e:
|
||||
@@ -60,10 +81,11 @@ def make_env(cfg: EnvConfig, n_envs: int = 1, use_async_envs: bool = False) -> g
|
||||
|
||||
gym_handle = f"{package_name}/{cfg.task}"
|
||||
|
||||
# batched version of the env that returns an observation of shape (b, c)
|
||||
env_cls = gym.vector.AsyncVectorEnv if use_async_envs else gym.vector.SyncVectorEnv
|
||||
env = env_cls(
|
||||
[lambda: gym.make(gym_handle, disable_env_checker=True, **cfg.gym_kwargs) for _ in range(n_envs)]
|
||||
)
|
||||
def _make_one():
|
||||
return gym.make(gym_handle, disable_env_checker=cfg.disable_env_checker, **(cfg.gym_kwargs or {}))
|
||||
|
||||
return env
|
||||
vec = env_cls([_make_one for _ in range(n_envs)])
|
||||
|
||||
# normalize to {suite: {task_id: vec_env}} for consistency
|
||||
suite_name = cfg.type # e.g., "pusht", "aloha"
|
||||
return {suite_name: {0: vec}}
|
||||
|
||||
377
src/lerobot/envs/libero.py
Normal file
377
src/lerobot/envs/libero.py
Normal file
@@ -0,0 +1,377 @@
|
||||
#!/usr/bin/env python
|
||||
|
||||
# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
from __future__ import annotations
|
||||
|
||||
import os
|
||||
from collections import defaultdict
|
||||
from collections.abc import Callable, Iterable, Mapping, Sequence
|
||||
from functools import partial
|
||||
from pathlib import Path
|
||||
from typing import Any
|
||||
|
||||
import gymnasium as gym
|
||||
import numpy as np
|
||||
import torch
|
||||
from gymnasium import spaces
|
||||
from libero.libero import benchmark, get_libero_path
|
||||
from libero.libero.envs import OffScreenRenderEnv
|
||||
from robosuite.utils.transform_utils import quat2axisangle
|
||||
|
||||
|
||||
def _parse_camera_names(camera_name: str | Sequence[str]) -> list[str]:
|
||||
"""Normalize camera_name into a non-empty list of strings."""
|
||||
if isinstance(camera_name, str):
|
||||
cams = [c.strip() for c in camera_name.split(",") if c.strip()]
|
||||
elif isinstance(camera_name, (list, tuple)):
|
||||
cams = [str(c).strip() for c in camera_name if str(c).strip()]
|
||||
else:
|
||||
raise TypeError(f"camera_name must be str or sequence[str], got {type(camera_name).__name__}")
|
||||
if not cams:
|
||||
raise ValueError("camera_name resolved to an empty list.")
|
||||
return cams
|
||||
|
||||
|
||||
def _get_suite(name: str) -> benchmark.Benchmark:
|
||||
"""Instantiate a LIBERO suite by name with clear validation."""
|
||||
bench = benchmark.get_benchmark_dict()
|
||||
if name not in bench:
|
||||
raise ValueError(f"Unknown LIBERO suite '{name}'. Available: {', '.join(sorted(bench.keys()))}")
|
||||
suite = bench[name]()
|
||||
if not getattr(suite, "tasks", None):
|
||||
raise ValueError(f"Suite '{name}' has no tasks.")
|
||||
return suite
|
||||
|
||||
|
||||
def _select_task_ids(total_tasks: int, task_ids: Iterable[int] | None) -> list[int]:
|
||||
"""Validate/normalize task ids. If None → all tasks."""
|
||||
if task_ids is None:
|
||||
return list(range(total_tasks))
|
||||
ids = sorted({int(t) for t in task_ids})
|
||||
for t in ids:
|
||||
if t < 0 or t >= total_tasks:
|
||||
raise ValueError(f"task_id {t} out of range [0, {total_tasks - 1}].")
|
||||
return ids
|
||||
|
||||
|
||||
def get_task_init_states(task_suite: Any, i: int) -> np.ndarray:
|
||||
init_states_path = (
|
||||
Path(get_libero_path("init_states"))
|
||||
/ task_suite.tasks[i].problem_folder
|
||||
/ task_suite.tasks[i].init_states_file
|
||||
)
|
||||
init_states = torch.load(init_states_path, weights_only=False) # nosec B614
|
||||
return init_states
|
||||
|
||||
|
||||
def get_libero_dummy_action():
|
||||
"""Get dummy/no-op action, used to roll out the simulation while the robot does nothing."""
|
||||
return [0, 0, 0, 0, 0, 0, -1]
|
||||
|
||||
|
||||
OBS_STATE_DIM = 8
|
||||
ACTION_DIM = 7
|
||||
AGENT_POS_LOW = -1000.0
|
||||
AGENT_POS_HIGH = 1000.0
|
||||
ACTION_LOW = -1.0
|
||||
ACTION_HIGH = 1.0
|
||||
TASK_SUITE_MAX_STEPS: dict[str, int] = {
|
||||
"libero_spatial": 280, # longest training demo has 193 steps
|
||||
"libero_object": 280, # longest training demo has 254 steps
|
||||
"libero_goal": 300, # longest training demo has 270 steps
|
||||
"libero_10": 520, # longest training demo has 505 steps
|
||||
"libero_90": 400, # longest training demo has 373 steps
|
||||
}
|
||||
|
||||
|
||||
class LiberoEnv(gym.Env):
|
||||
metadata = {"render_modes": ["rgb_array"], "render_fps": 80}
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
task_suite: Any,
|
||||
task_id: int,
|
||||
task_suite_name: str,
|
||||
camera_name: str | Sequence[str] = "agentview_image,robot0_eye_in_hand_image",
|
||||
obs_type: str = "pixels",
|
||||
render_mode: str = "rgb_array",
|
||||
observation_width: int = 256,
|
||||
observation_height: int = 256,
|
||||
visualization_width: int = 640,
|
||||
visualization_height: int = 480,
|
||||
init_states: bool = True,
|
||||
episode_index: int = 0,
|
||||
camera_name_mapping: dict[str, str] | None = None,
|
||||
num_steps_wait: int = 10,
|
||||
):
|
||||
super().__init__()
|
||||
self.task_id = task_id
|
||||
self.obs_type = obs_type
|
||||
self.render_mode = render_mode
|
||||
self.observation_width = observation_width
|
||||
self.observation_height = observation_height
|
||||
self.visualization_width = visualization_width
|
||||
self.visualization_height = visualization_height
|
||||
self.init_states = init_states
|
||||
self.camera_name = _parse_camera_names(
|
||||
camera_name
|
||||
) # agentview_image (main) or robot0_eye_in_hand_image (wrist)
|
||||
|
||||
# Map raw camera names to "image1" and "image2".
|
||||
# The preprocessing step `preprocess_observation` will then prefix these with `.images.*`,
|
||||
# following the LeRobot convention (e.g., `observation.images.image`, `observation.images.image2`).
|
||||
# This ensures the policy consistently receives observations in the
|
||||
# expected format regardless of the original camera naming.
|
||||
if camera_name_mapping is None:
|
||||
camera_name_mapping = {
|
||||
"agentview_image": "image",
|
||||
"robot0_eye_in_hand_image": "image2",
|
||||
}
|
||||
self.camera_name_mapping = camera_name_mapping
|
||||
self.num_steps_wait = num_steps_wait
|
||||
self.episode_index = episode_index
|
||||
# Load once and keep
|
||||
self._init_states = get_task_init_states(task_suite, self.task_id) if self.init_states else None
|
||||
self._init_state_id = self.episode_index # tie each sub-env to a fixed init state
|
||||
|
||||
self._env = self._make_envs_task(task_suite, self.task_id)
|
||||
default_steps = 500
|
||||
self._max_episode_steps = TASK_SUITE_MAX_STEPS.get(task_suite_name, default_steps)
|
||||
|
||||
images = {}
|
||||
for cam in self.camera_name:
|
||||
images[self.camera_name_mapping[cam]] = spaces.Box(
|
||||
low=0,
|
||||
high=255,
|
||||
shape=(self.observation_height, self.observation_width, 3),
|
||||
dtype=np.uint8,
|
||||
)
|
||||
|
||||
if self.obs_type == "state":
|
||||
raise NotImplementedError(
|
||||
"The 'state' observation type is not supported in LiberoEnv. "
|
||||
"Please switch to an image-based obs_type (e.g. 'pixels', 'pixels_agent_pos')."
|
||||
)
|
||||
|
||||
elif self.obs_type == "pixels":
|
||||
self.observation_space = spaces.Dict(
|
||||
{
|
||||
"pixels": spaces.Dict(images),
|
||||
}
|
||||
)
|
||||
elif self.obs_type == "pixels_agent_pos":
|
||||
self.observation_space = spaces.Dict(
|
||||
{
|
||||
"pixels": spaces.Dict(images),
|
||||
"agent_pos": spaces.Box(
|
||||
low=AGENT_POS_LOW,
|
||||
high=AGENT_POS_HIGH,
|
||||
shape=(OBS_STATE_DIM,),
|
||||
dtype=np.float64,
|
||||
),
|
||||
}
|
||||
)
|
||||
|
||||
self.action_space = spaces.Box(
|
||||
low=ACTION_LOW, high=ACTION_HIGH, shape=(ACTION_DIM,), dtype=np.float32
|
||||
)
|
||||
|
||||
def render(self):
|
||||
raw_obs = self._env.env._get_observations()
|
||||
image = self._format_raw_obs(raw_obs)["pixels"]["image"]
|
||||
return image
|
||||
|
||||
def _make_envs_task(self, task_suite: Any, task_id: int = 0):
|
||||
task = task_suite.get_task(task_id)
|
||||
self.task = task.name
|
||||
self.task_description = task.language
|
||||
task_bddl_file = os.path.join(get_libero_path("bddl_files"), task.problem_folder, task.bddl_file)
|
||||
|
||||
env_args = {
|
||||
"bddl_file_name": task_bddl_file,
|
||||
"camera_heights": self.observation_height,
|
||||
"camera_widths": self.observation_width,
|
||||
}
|
||||
env = OffScreenRenderEnv(**env_args)
|
||||
env.reset()
|
||||
return env
|
||||
|
||||
def _format_raw_obs(self, raw_obs: dict[str, Any]) -> dict[str, Any]:
|
||||
images = {}
|
||||
for camera_name in self.camera_name:
|
||||
image = raw_obs[camera_name]
|
||||
image = image[::-1, ::-1] # rotate 180 degrees
|
||||
images[self.camera_name_mapping[camera_name]] = image
|
||||
state = np.concatenate(
|
||||
(
|
||||
raw_obs["robot0_eef_pos"],
|
||||
quat2axisangle(raw_obs["robot0_eef_quat"]),
|
||||
raw_obs["robot0_gripper_qpos"],
|
||||
)
|
||||
)
|
||||
agent_pos = state
|
||||
if self.obs_type == "pixels":
|
||||
return {"pixels": images.copy()}
|
||||
if self.obs_type == "pixels_agent_pos":
|
||||
return {
|
||||
"pixels": images.copy(),
|
||||
"agent_pos": agent_pos,
|
||||
}
|
||||
raise NotImplementedError(
|
||||
f"The observation type '{self.obs_type}' is not supported in LiberoEnv. "
|
||||
"Please switch to an image-based obs_type (e.g. 'pixels', 'pixels_agent_pos')."
|
||||
)
|
||||
|
||||
def reset(self, seed=None, **kwargs):
|
||||
super().reset(seed=seed)
|
||||
self._env.seed(seed)
|
||||
if self.init_states and self._init_states is not None:
|
||||
self._env.set_init_state(self._init_states[self._init_state_id])
|
||||
raw_obs = self._env.reset()
|
||||
|
||||
# After reset, objects may be unstable (slightly floating, intersecting, etc.).
|
||||
# Step the simulator with a no-op action for a few frames so everything settles.
|
||||
# Increasing this value can improve determinism and reproducibility across resets.
|
||||
for _ in range(self.num_steps_wait):
|
||||
raw_obs, _, _, _ = self._env.step(get_libero_dummy_action())
|
||||
observation = self._format_raw_obs(raw_obs)
|
||||
info = {"is_success": False}
|
||||
return observation, info
|
||||
|
||||
def step(self, action: np.ndarray) -> tuple[dict[str, Any], float, bool, bool, dict[str, Any]]:
|
||||
if action.ndim != 1:
|
||||
raise ValueError(
|
||||
f"Expected action to be 1-D (shape (action_dim,)), "
|
||||
f"but got shape {action.shape} with ndim={action.ndim}"
|
||||
)
|
||||
raw_obs, reward, done, info = self._env.step(action)
|
||||
|
||||
is_success = self._env.check_success()
|
||||
terminated = done or is_success
|
||||
info["is_success"] = is_success
|
||||
|
||||
observation = self._format_raw_obs(raw_obs)
|
||||
if done:
|
||||
self.reset()
|
||||
info.update(
|
||||
{
|
||||
"task": self.task,
|
||||
"task_id": self.task_id,
|
||||
"done": done,
|
||||
"is_success": is_success,
|
||||
}
|
||||
)
|
||||
truncated = False
|
||||
return observation, reward, terminated, truncated, info
|
||||
|
||||
def close(self):
|
||||
self._env.close()
|
||||
|
||||
|
||||
def _make_env_fns(
|
||||
*,
|
||||
suite,
|
||||
suite_name: str,
|
||||
task_id: int,
|
||||
n_envs: int,
|
||||
camera_names: list[str],
|
||||
init_states: bool,
|
||||
gym_kwargs: Mapping[str, Any],
|
||||
) -> list[Callable[[], LiberoEnv]]:
|
||||
"""Build n_envs factory callables for a single (suite, task_id)."""
|
||||
|
||||
def _make_env(episode_index: int, **kwargs) -> LiberoEnv:
|
||||
local_kwargs = dict(kwargs)
|
||||
return LiberoEnv(
|
||||
task_suite=suite,
|
||||
task_id=task_id,
|
||||
task_suite_name=suite_name,
|
||||
camera_name=camera_names,
|
||||
init_states=init_states,
|
||||
episode_index=episode_index,
|
||||
**local_kwargs,
|
||||
)
|
||||
|
||||
fns: list[Callable[[], LiberoEnv]] = []
|
||||
for episode_index in range(n_envs):
|
||||
fns.append(partial(_make_env, episode_index, **gym_kwargs))
|
||||
return fns
|
||||
|
||||
|
||||
# ---- Main API ----------------------------------------------------------------
|
||||
|
||||
|
||||
def create_libero_envs(
|
||||
task: str,
|
||||
n_envs: int,
|
||||
gym_kwargs: dict[str, Any] | None = None,
|
||||
camera_name: str | Sequence[str] = "agentview_image,robot0_eye_in_hand_image",
|
||||
init_states: bool = True,
|
||||
env_cls: Callable[[Sequence[Callable[[], Any]]], Any] | None = None,
|
||||
) -> dict[str, dict[int, Any]]:
|
||||
"""
|
||||
Create vectorized LIBERO environments with a consistent return shape.
|
||||
|
||||
Returns:
|
||||
dict[suite_name][task_id] -> vec_env (env_cls([...]) with exactly n_envs factories)
|
||||
Notes:
|
||||
- n_envs is the number of rollouts *per task* (episode_index = 0..n_envs-1).
|
||||
- `task` can be a single suite or a comma-separated list of suites.
|
||||
- You may pass `task_ids` (list[int]) inside `gym_kwargs` to restrict tasks per suite.
|
||||
"""
|
||||
if env_cls is None or not callable(env_cls):
|
||||
raise ValueError("env_cls must be a callable that wraps a list of environment factory callables.")
|
||||
if not isinstance(n_envs, int) or n_envs <= 0:
|
||||
raise ValueError(f"n_envs must be a positive int; got {n_envs}.")
|
||||
|
||||
gym_kwargs = dict(gym_kwargs or {})
|
||||
task_ids_filter = gym_kwargs.pop("task_ids", None) # optional: limit to specific tasks
|
||||
|
||||
camera_names = _parse_camera_names(camera_name)
|
||||
suite_names = [s.strip() for s in str(task).split(",") if s.strip()]
|
||||
if not suite_names:
|
||||
raise ValueError("`task` must contain at least one LIBERO suite name.")
|
||||
|
||||
print(
|
||||
f"Creating LIBERO envs | suites={suite_names} | n_envs(per task)={n_envs} | init_states={init_states}"
|
||||
)
|
||||
if task_ids_filter is not None:
|
||||
print(f"Restricting to task_ids={task_ids_filter}")
|
||||
|
||||
out: dict[str, dict[int, Any]] = defaultdict(dict)
|
||||
|
||||
for suite_name in suite_names:
|
||||
suite = _get_suite(suite_name)
|
||||
total = len(suite.tasks)
|
||||
selected = _select_task_ids(total, task_ids_filter)
|
||||
|
||||
if not selected:
|
||||
raise ValueError(f"No tasks selected for suite '{suite_name}' (available: {total}).")
|
||||
|
||||
for tid in selected:
|
||||
fns = _make_env_fns(
|
||||
suite=suite,
|
||||
suite_name=suite_name,
|
||||
task_id=tid,
|
||||
n_envs=n_envs,
|
||||
camera_names=camera_names,
|
||||
init_states=init_states,
|
||||
gym_kwargs=gym_kwargs,
|
||||
)
|
||||
out[suite_name][tid] = env_cls(fns)
|
||||
print(f"Built vec env | suite={suite_name} | task_id={tid} | n_envs={n_envs}")
|
||||
|
||||
# return plain dicts for predictability
|
||||
return {suite: dict(task_map) for suite, task_map in out.items()}
|
||||
@@ -14,6 +14,8 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import warnings
|
||||
from collections.abc import Mapping, Sequence
|
||||
from functools import singledispatch
|
||||
from typing import Any
|
||||
|
||||
import einops
|
||||
@@ -154,3 +156,41 @@ def add_envs_task(env: gym.vector.VectorEnv, observation: dict[str, Any]) -> dic
|
||||
num_envs = observation[list(observation.keys())[0]].shape[0]
|
||||
observation["task"] = ["" for _ in range(num_envs)]
|
||||
return observation
|
||||
|
||||
|
||||
def _close_single_env(env: Any) -> None:
|
||||
try:
|
||||
env.close()
|
||||
except Exception as exc:
|
||||
print(f"Exception while closing env {env}: {exc}")
|
||||
|
||||
|
||||
@singledispatch
|
||||
def close_envs(obj: Any) -> None:
|
||||
"""Default: raise if the type is not recognized."""
|
||||
raise NotImplementedError(f"close_envs not implemented for type {type(obj).__name__}")
|
||||
|
||||
|
||||
@close_envs.register
|
||||
def _(env: Mapping) -> None:
|
||||
for v in env.values():
|
||||
if isinstance(v, Mapping):
|
||||
close_envs(v)
|
||||
elif hasattr(v, "close"):
|
||||
_close_single_env(v)
|
||||
|
||||
|
||||
@close_envs.register
|
||||
def _(envs: Sequence) -> None:
|
||||
if isinstance(envs, (str, bytes)):
|
||||
return
|
||||
for v in envs:
|
||||
if isinstance(v, Mapping) or isinstance(v, Sequence) and not isinstance(v, (str, bytes)):
|
||||
close_envs(v)
|
||||
elif hasattr(v, "close"):
|
||||
_close_single_env(v)
|
||||
|
||||
|
||||
@close_envs.register
|
||||
def _(env: gym.Env) -> None:
|
||||
_close_single_env(env)
|
||||
|
||||
@@ -46,17 +46,20 @@ Note that in both examples, the repo/folder should contain at least `config.json
|
||||
You can learn about the CLI options for this script in the `EvalPipelineConfig` in lerobot/configs/eval.py
|
||||
"""
|
||||
|
||||
import concurrent.futures as cf
|
||||
import json
|
||||
import logging
|
||||
import threading
|
||||
import time
|
||||
from collections import defaultdict
|
||||
from collections.abc import Callable
|
||||
from contextlib import nullcontext
|
||||
from copy import deepcopy
|
||||
from dataclasses import asdict
|
||||
from functools import partial
|
||||
from pathlib import Path
|
||||
from pprint import pformat
|
||||
from typing import Any
|
||||
from typing import Any, TypedDict
|
||||
|
||||
import einops
|
||||
import gymnasium as gym
|
||||
@@ -69,7 +72,12 @@ from tqdm import trange
|
||||
from lerobot.configs import parser
|
||||
from lerobot.configs.eval import EvalPipelineConfig
|
||||
from lerobot.envs.factory import make_env
|
||||
from lerobot.envs.utils import add_envs_task, check_env_attributes_and_types, preprocess_observation
|
||||
from lerobot.envs.utils import (
|
||||
add_envs_task,
|
||||
check_env_attributes_and_types,
|
||||
close_envs,
|
||||
preprocess_observation,
|
||||
)
|
||||
from lerobot.policies.factory import make_policy, make_pre_post_processors
|
||||
from lerobot.policies.pretrained import PreTrainedPolicy
|
||||
from lerobot.processor import PolicyAction, PolicyProcessorPipeline
|
||||
@@ -147,7 +155,7 @@ def rollout(
|
||||
leave=False,
|
||||
)
|
||||
check_env_attributes_and_types(env)
|
||||
while not np.all(done):
|
||||
while not np.all(done) and step < max_steps:
|
||||
# Numpy array to tensor and changing dictionary keys to LeRobot policy format.
|
||||
observation = preprocess_observation(observation)
|
||||
if return_observations:
|
||||
@@ -178,7 +186,12 @@ def rollout(
|
||||
successes = [False] * env.num_envs
|
||||
|
||||
# Keep track of which environments are done so far.
|
||||
# Mark the episode as done if we reach the maximum step limit.
|
||||
# This ensures that the rollout always terminates cleanly at `max_steps`,
|
||||
# and allows logging/saving (e.g., videos) to be triggered consistently.
|
||||
done = terminated | truncated | done
|
||||
if step + 1 == max_steps:
|
||||
done = np.ones_like(done, dtype=bool)
|
||||
|
||||
all_actions.append(torch.from_numpy(action_numpy))
|
||||
all_rewards.append(torch.from_numpy(reward))
|
||||
@@ -474,7 +487,7 @@ def eval_main(cfg: EvalPipelineConfig):
|
||||
logging.info(colored("Output dir:", "yellow", attrs=["bold"]) + f" {cfg.output_dir}")
|
||||
|
||||
logging.info("Making environment.")
|
||||
env = make_env(cfg.env, n_envs=cfg.eval.batch_size, use_async_envs=cfg.eval.use_async_envs)
|
||||
envs = make_env(cfg.env, n_envs=cfg.eval.batch_size, use_async_envs=cfg.eval.use_async_envs)
|
||||
|
||||
logging.info("Making policy.")
|
||||
|
||||
@@ -490,10 +503,9 @@ def eval_main(cfg: EvalPipelineConfig):
|
||||
# The inference device is automatically set to match the detected hardware, overriding any previous device settings from training to ensure compatibility.
|
||||
preprocessor_overrides={"device_processor": {"device": str(policy.config.device)}},
|
||||
)
|
||||
|
||||
with torch.no_grad(), torch.autocast(device_type=device.type) if cfg.policy.use_amp else nullcontext():
|
||||
info = eval_policy(
|
||||
env=env,
|
||||
info = eval_policy_all(
|
||||
envs=envs,
|
||||
policy=policy,
|
||||
preprocessor=preprocessor,
|
||||
postprocessor=postprocessor,
|
||||
@@ -501,18 +513,237 @@ def eval_main(cfg: EvalPipelineConfig):
|
||||
max_episodes_rendered=10,
|
||||
videos_dir=Path(cfg.output_dir) / "videos",
|
||||
start_seed=cfg.seed,
|
||||
max_parallel_tasks=cfg.env.max_parallel_tasks,
|
||||
)
|
||||
print(info["aggregated"])
|
||||
print("Overall Aggregated Metrics:")
|
||||
print(info["overall"])
|
||||
|
||||
# Print per-suite stats
|
||||
for task_group, task_group_info in info.items():
|
||||
print(f"\nAggregated Metrics for {task_group}:")
|
||||
print(task_group_info)
|
||||
# Close all vec envs
|
||||
close_envs(envs)
|
||||
|
||||
# Save info
|
||||
with open(Path(cfg.output_dir) / "eval_info.json", "w") as f:
|
||||
json.dump(info, f, indent=2)
|
||||
|
||||
env.close()
|
||||
|
||||
logging.info("End of eval")
|
||||
|
||||
|
||||
# ---- typed payload returned by one task eval ----
|
||||
class TaskMetrics(TypedDict):
|
||||
sum_rewards: list[float]
|
||||
max_rewards: list[float]
|
||||
successes: list[bool]
|
||||
video_paths: list[str]
|
||||
|
||||
|
||||
ACC_KEYS = ("sum_rewards", "max_rewards", "successes", "video_paths")
|
||||
|
||||
|
||||
def eval_one(
|
||||
env: gym.vector.VectorEnv,
|
||||
*,
|
||||
policy: PreTrainedPolicy,
|
||||
preprocessor: PolicyProcessorPipeline[dict[str, Any], dict[str, Any]],
|
||||
postprocessor: PolicyProcessorPipeline[PolicyAction, PolicyAction],
|
||||
n_episodes: int,
|
||||
max_episodes_rendered: int,
|
||||
videos_dir: Path | None,
|
||||
return_episode_data: bool,
|
||||
start_seed: int | None,
|
||||
) -> TaskMetrics:
|
||||
"""Evaluates one task_id of one suite using the provided vec env."""
|
||||
|
||||
task_videos_dir = videos_dir
|
||||
|
||||
task_result = eval_policy(
|
||||
env=env,
|
||||
policy=policy,
|
||||
preprocessor=preprocessor,
|
||||
postprocessor=postprocessor,
|
||||
n_episodes=n_episodes,
|
||||
max_episodes_rendered=max_episodes_rendered,
|
||||
videos_dir=task_videos_dir,
|
||||
return_episode_data=return_episode_data,
|
||||
start_seed=start_seed,
|
||||
)
|
||||
|
||||
per_episode = task_result["per_episode"]
|
||||
return TaskMetrics(
|
||||
sum_rewards=[ep["sum_reward"] for ep in per_episode],
|
||||
max_rewards=[ep["max_reward"] for ep in per_episode],
|
||||
successes=[ep["success"] for ep in per_episode],
|
||||
video_paths=task_result.get("video_paths", []),
|
||||
)
|
||||
|
||||
|
||||
def run_one(
|
||||
task_group: str,
|
||||
task_id: int,
|
||||
env,
|
||||
*,
|
||||
policy,
|
||||
preprocessor,
|
||||
postprocessor,
|
||||
n_episodes: int,
|
||||
max_episodes_rendered: int,
|
||||
videos_dir: Path | None,
|
||||
return_episode_data: bool,
|
||||
start_seed: int | None,
|
||||
):
|
||||
"""
|
||||
Run eval_one for a single (task_group, task_id, env).
|
||||
Returns (task_group, task_id, task_metrics_dict).
|
||||
This function is intentionally module-level to make it easy to test.
|
||||
"""
|
||||
task_videos_dir = None
|
||||
if videos_dir is not None:
|
||||
task_videos_dir = videos_dir / f"{task_group}_{task_id}"
|
||||
task_videos_dir.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
# Call the existing eval_one (assumed to return TaskMetrics-like dict)
|
||||
metrics = eval_one(
|
||||
env,
|
||||
policy=policy,
|
||||
preprocessor=preprocessor,
|
||||
postprocessor=postprocessor,
|
||||
n_episodes=n_episodes,
|
||||
max_episodes_rendered=max_episodes_rendered,
|
||||
videos_dir=task_videos_dir,
|
||||
return_episode_data=return_episode_data,
|
||||
start_seed=start_seed,
|
||||
)
|
||||
# ensure we always provide video_paths key to simplify accumulation
|
||||
if max_episodes_rendered > 0:
|
||||
metrics.setdefault("video_paths", [])
|
||||
return task_group, task_id, metrics
|
||||
|
||||
|
||||
def eval_policy_all(
|
||||
envs: dict[str, dict[int, gym.vector.VectorEnv]],
|
||||
policy,
|
||||
preprocessor: PolicyProcessorPipeline[dict[str, Any], dict[str, Any]],
|
||||
postprocessor: PolicyProcessorPipeline[PolicyAction, PolicyAction],
|
||||
n_episodes: int,
|
||||
*,
|
||||
max_episodes_rendered: int = 0,
|
||||
videos_dir: Path | None = None,
|
||||
return_episode_data: bool = False,
|
||||
start_seed: int | None = None,
|
||||
max_parallel_tasks: int = 1,
|
||||
) -> dict:
|
||||
"""
|
||||
Evaluate a nested `envs` dict: {task_group: {task_id: vec_env}}.
|
||||
This implementation flattens tasks, runs them sequentially or via ThreadPoolExecutor,
|
||||
accumulates per-group and overall statistics, and returns the same aggregate metrics
|
||||
schema as the single-env evaluator (avg_sum_reward / avg_max_reward / pc_success / timings)
|
||||
plus per-task infos.
|
||||
"""
|
||||
start_t = time.time()
|
||||
|
||||
# Flatten envs into list of (task_group, task_id, env)
|
||||
tasks = [(tg, tid, vec) for tg, group in envs.items() for tid, vec in group.items()]
|
||||
|
||||
# accumulators: track metrics at both per-group level and across all groups
|
||||
group_acc: dict[str, dict[str, list]] = defaultdict(lambda: {k: [] for k in ACC_KEYS})
|
||||
overall: dict[str, list] = {k: [] for k in ACC_KEYS}
|
||||
per_task_infos: list[dict] = []
|
||||
|
||||
# small inline helper to accumulate one task's metrics into accumulators
|
||||
def _accumulate_to(group: str, metrics: dict):
|
||||
# metrics expected to contain 'sum_rewards', 'max_rewards', 'successes', optionally 'video_paths'
|
||||
# but eval_one may store per-episode lists; we assume metrics uses scalars averaged per task as before.
|
||||
# To be robust, accept scalars or lists.
|
||||
def _append(key, value):
|
||||
if value is None:
|
||||
return
|
||||
if isinstance(value, list):
|
||||
group_acc[group][key].extend(value)
|
||||
overall[key].extend(value)
|
||||
else:
|
||||
group_acc[group][key].append(value)
|
||||
overall[key].append(value)
|
||||
|
||||
_append("sum_rewards", metrics.get("sum_rewards"))
|
||||
_append("max_rewards", metrics.get("max_rewards"))
|
||||
_append("successes", metrics.get("successes"))
|
||||
# video_paths is list-like
|
||||
paths = metrics.get("video_paths", [])
|
||||
if paths:
|
||||
group_acc[group]["video_paths"].extend(paths)
|
||||
overall["video_paths"].extend(paths)
|
||||
|
||||
# Choose runner (sequential vs threaded)
|
||||
task_runner = partial(
|
||||
run_one,
|
||||
policy=policy,
|
||||
preprocessor=preprocessor,
|
||||
postprocessor=postprocessor,
|
||||
n_episodes=n_episodes,
|
||||
max_episodes_rendered=max_episodes_rendered,
|
||||
videos_dir=videos_dir,
|
||||
return_episode_data=return_episode_data,
|
||||
start_seed=start_seed,
|
||||
)
|
||||
|
||||
if max_parallel_tasks <= 1:
|
||||
# sequential path (single accumulator path on the main thread)
|
||||
# NOTE: keeping a single-threaded accumulator avoids concurrent list appends or locks
|
||||
for task_group, task_id, env in tasks:
|
||||
tg, tid, metrics = task_runner(task_group, task_id, env)
|
||||
_accumulate_to(tg, metrics)
|
||||
per_task_infos.append({"task_group": tg, "task_id": tid, "metrics": metrics})
|
||||
else:
|
||||
# threaded path: submit all tasks, consume completions on main thread and accumulate there
|
||||
with cf.ThreadPoolExecutor(max_workers=max_parallel_tasks) as executor:
|
||||
fut2meta = {}
|
||||
for task_group, task_id, env in tasks:
|
||||
fut = executor.submit(task_runner, task_group, task_id, env)
|
||||
fut2meta[fut] = (task_group, task_id)
|
||||
for fut in cf.as_completed(fut2meta):
|
||||
tg, tid, metrics = fut.result()
|
||||
_accumulate_to(tg, metrics)
|
||||
per_task_infos.append({"task_group": tg, "task_id": tid, "metrics": metrics})
|
||||
|
||||
# compute aggregated metrics helper (robust to lists/scalars)
|
||||
def _agg_from_list(xs):
|
||||
if not xs:
|
||||
return float("nan")
|
||||
arr = np.array(xs, dtype=float)
|
||||
return float(np.nanmean(arr))
|
||||
|
||||
# compute per-group aggregates
|
||||
groups_aggregated = {}
|
||||
for group, acc in group_acc.items():
|
||||
groups_aggregated[group] = {
|
||||
"avg_sum_reward": _agg_from_list(acc["sum_rewards"]),
|
||||
"avg_max_reward": _agg_from_list(acc["max_rewards"]),
|
||||
"pc_success": _agg_from_list(acc["successes"]) * 100 if acc["successes"] else float("nan"),
|
||||
"n_episodes": len(acc["sum_rewards"]),
|
||||
"video_paths": list(acc["video_paths"]),
|
||||
}
|
||||
|
||||
# overall aggregates
|
||||
overall_agg = {
|
||||
"avg_sum_reward": _agg_from_list(overall["sum_rewards"]),
|
||||
"avg_max_reward": _agg_from_list(overall["max_rewards"]),
|
||||
"pc_success": _agg_from_list(overall["successes"]) * 100 if overall["successes"] else float("nan"),
|
||||
"n_episodes": len(overall["sum_rewards"]),
|
||||
"eval_s": time.time() - start_t,
|
||||
"eval_ep_s": (time.time() - start_t) / max(1, len(overall["sum_rewards"])),
|
||||
"video_paths": list(overall["video_paths"]),
|
||||
}
|
||||
|
||||
return {
|
||||
"per_task": per_task_infos,
|
||||
"per_group": groups_aggregated,
|
||||
"overall": overall_agg,
|
||||
}
|
||||
|
||||
|
||||
def main():
|
||||
init_logging()
|
||||
eval_main()
|
||||
|
||||
@@ -30,11 +30,12 @@ from lerobot.datasets.factory import make_dataset
|
||||
from lerobot.datasets.sampler import EpisodeAwareSampler
|
||||
from lerobot.datasets.utils import cycle
|
||||
from lerobot.envs.factory import make_env
|
||||
from lerobot.envs.utils import close_envs
|
||||
from lerobot.optim.factory import make_optimizer_and_scheduler
|
||||
from lerobot.policies.factory import make_policy, make_pre_post_processors
|
||||
from lerobot.policies.pretrained import PreTrainedPolicy
|
||||
from lerobot.policies.utils import get_device_from_parameters
|
||||
from lerobot.scripts.eval import eval_policy
|
||||
from lerobot.scripts.eval import eval_policy_all
|
||||
from lerobot.utils.logging_utils import AverageMeter, MetricsTracker
|
||||
from lerobot.utils.random_utils import set_seed
|
||||
from lerobot.utils.train_utils import (
|
||||
@@ -302,8 +303,8 @@ def train(cfg: TrainPipelineConfig):
|
||||
torch.no_grad(),
|
||||
torch.autocast(device_type=device.type) if cfg.policy.use_amp else nullcontext(),
|
||||
):
|
||||
eval_info = eval_policy(
|
||||
env=eval_env,
|
||||
eval_info = eval_policy_all(
|
||||
envs=eval_env, # dict[suite][task_id] -> vec_env
|
||||
policy=policy,
|
||||
preprocessor=preprocessor,
|
||||
postprocessor=postprocessor,
|
||||
@@ -311,8 +312,16 @@ def train(cfg: TrainPipelineConfig):
|
||||
videos_dir=cfg.output_dir / "eval" / f"videos_step_{step_id}",
|
||||
max_episodes_rendered=4,
|
||||
start_seed=cfg.seed,
|
||||
max_parallel_tasks=cfg.env.max_parallel_tasks,
|
||||
)
|
||||
# overall metrics (suite-agnostic)
|
||||
aggregated = eval_info["overall"]
|
||||
|
||||
# optional: per-suite logging
|
||||
for suite, suite_info in eval_info.items():
|
||||
logging.info("Suite %s aggregated: %s", suite, suite_info)
|
||||
|
||||
# meters/tracker
|
||||
eval_metrics = {
|
||||
"avg_sum_reward": AverageMeter("∑rwrd", ":.3f"),
|
||||
"pc_success": AverageMeter("success", ":.1f"),
|
||||
@@ -321,17 +330,16 @@ def train(cfg: TrainPipelineConfig):
|
||||
eval_tracker = MetricsTracker(
|
||||
cfg.batch_size, dataset.num_frames, dataset.num_episodes, eval_metrics, initial_step=step
|
||||
)
|
||||
eval_tracker.eval_s = eval_info["aggregated"].pop("eval_s")
|
||||
eval_tracker.avg_sum_reward = eval_info["aggregated"].pop("avg_sum_reward")
|
||||
eval_tracker.pc_success = eval_info["aggregated"].pop("pc_success")
|
||||
logging.info(eval_tracker)
|
||||
eval_tracker.eval_s = aggregated.pop("eval_s")
|
||||
eval_tracker.avg_sum_reward = aggregated.pop("avg_sum_reward")
|
||||
eval_tracker.pc_success = aggregated.pop("pc_success")
|
||||
if wandb_logger:
|
||||
wandb_log_dict = {**eval_tracker.to_dict(), **eval_info}
|
||||
wandb_logger.log_dict(wandb_log_dict, step, mode="eval")
|
||||
wandb_logger.log_video(eval_info["video_paths"][0], step, mode="eval")
|
||||
wandb_logger.log_video(eval_info["overall"]["video_paths"][0], step, mode="eval")
|
||||
|
||||
if eval_env:
|
||||
eval_env.close()
|
||||
close_envs(eval_env)
|
||||
logging.info("End of training")
|
||||
|
||||
if cfg.policy.push_to_hub:
|
||||
|
||||
@@ -46,7 +46,10 @@ def test_env(env_name, env_task, obs_type):
|
||||
@require_env
|
||||
def test_factory(env_name):
|
||||
cfg = make_env_config(env_name)
|
||||
env = make_env(cfg, n_envs=1)
|
||||
envs = make_env(cfg, n_envs=1)
|
||||
suite_name = next(iter(envs))
|
||||
task_id = next(iter(envs[suite_name]))
|
||||
env = envs[suite_name][task_id]
|
||||
obs, _ = env.reset()
|
||||
obs = preprocess_observation(obs)
|
||||
|
||||
|
||||
@@ -159,7 +159,7 @@ def test_policy(ds_repo_id, env_name, env_kwargs, policy_name, policy_kwargs):
|
||||
assert isinstance(policy, PreTrainedPolicy)
|
||||
|
||||
# Check that we run select_actions and get the appropriate output.
|
||||
env = make_env(train_cfg.env, n_envs=2)
|
||||
envs = make_env(train_cfg.env, n_envs=2)
|
||||
|
||||
dataloader = torch.utils.data.DataLoader(
|
||||
dataset,
|
||||
@@ -188,6 +188,12 @@ def test_policy(ds_repo_id, env_name, env_kwargs, policy_name, policy_kwargs):
|
||||
|
||||
# reset the policy and environment
|
||||
policy.reset()
|
||||
# For testing purposes, we only need a single environment instance.
|
||||
# So here we unwrap the first suite_name and first task_id to grab
|
||||
# the actual env object (SyncVectorEnv) that exposes `.reset()`.
|
||||
suite_name = next(iter(envs))
|
||||
task_id = next(iter(envs[suite_name]))
|
||||
env = envs[suite_name][task_id]
|
||||
observation, _ = env.reset(seed=train_cfg.seed)
|
||||
|
||||
# apply transform to normalize the observations
|
||||
|
||||
Reference in New Issue
Block a user